Написал я тут обобщённый метод, который выглядит так:
private <T> T getParamValue(ProceedingJoinPoint joinPoint, String name) { if (! (joinPoint.getSignature() instanceof CodeSignature)) throw new RuntimeException( "JoinPoint is not a method." ); String[] parameterNames = (( CodeSignature ) joinPoint.getSignature()).getParameterNames(); int index = -1; for (int i = 0; i < parameterNames.length; i++) { if (parameterNames[i].equals( name )) { index = i; break; } } if (-1 == index) throw new RuntimeException( String.format( "Parameter '%s' not found.", name ) ); return ( T ) joinPoint.getArgs()[index]; } |
В принципе, тело метода мало чем интересно. Интересен оператор return, который выполняет приведение типа к T. Мне захотелось разобраться, как работает этот cast и почему эта конструкция работоспособна с любым типом T. Известно, что в java оператор приведения типа может привести к ClassCastException во время выполнения, однако с другой стороны мы знаем, что джавские дженерики компилируются таким образом, что в class-файлах информации о типах не остаётся, и компилятор не может добавить в код метода инструкцию приведения типа к типу T. Значит, скорее всего, приведение типа к типу-аргументу не порождает байткод, в отличие от обычного приведения к конкретному типу, известному на момент компиляции. Эту гипотезу легко проверить, берём декомпилятор, и – да, действительно, он декомпилирует последнюю строчку как
return joinPoint.getArgs()[index]; |
Как мы видим, компилятор сгенерировал метод, возвращающий Object, а для того, чтобы что-то превратить в Object, не нужно выполнять checkcast (байткод операции проверки приведения типа). Так и работают обобщения в Java. Компилятор превращает переменные типов T в переменные типа Object, и при присвоении
T var = someObject; |
компилятор генерирует код
Object var = someObject; |
А вот когда наоборот объект обобщённого типа мы присваиваем переменной конкретного типа, то компилятор добавляет байткод checkcast:
String str = this.<String>getParamValue(); |
превращается в
String str = (String) this.getParamValue(); // this.getParamValue() возвращает Object |
Так всё и работает. Поэтому в принципе не так уж и важно, правильно ли компилятор выведет тип при вызове getParamValue(). В любом случае будет вызов метода, возвращающего Object, и последующий каст к конкретному типу переменной (поля, аргумента функции).
Примитивные типы обрабатываются несколько особым образом. Допустим, мы вызываем наш метод и пытаемся присводить результат переменной-примитиву:
long id = getParamValue(); |
Кажется, что здесь может потребоваться явное указание типа T, так как long не может выступать в качестве типа-аргумента, однако компилятор достаточно умён и выполнит вывод ссылочного типа Long, соответствующего примитивному типу long, автоматически, и ещё добавит анбоксинг:
long id = ((Long) getParamValue()).longValue(); |
Осталось рассмотреть предупреждение компилятора “Unchecked cast: X to Y”, которое выдается при компиляции кода, преобразующего Object в обобщённый тип, либо в тип, зависящий от обобщённого типа:
List<String> list = (List<String>) map.get("list"); |
Теперь нам понятно, почему компилятор выдаёт это предупреждение. Инструкция checkcast добавляется в сгенерированный байткод, но она проверяет только то, что объект является списком List. Но то, что этот список был создан с типом-аргументом String, эта инструкция проверить не может. Аналогичное предупреждение мы получаем в строчке
return ( T ) joinPoint.getArgs()[index]; |
– и тут компилятор вообще ничем не может нам помочь, поскольку информация о T будет недоступна во время выполнения, переменная будет иметь тип Object, и мы не сможем быть уверены, что там хранится объект типа T, а не что-либо другое.
Для демонстрации возможностей console framework я долго думал над тем, чтобы написать какое-нибудь небольшое приложение, которые с одной стороны было бы достаточно функциональным (чтобы продемонстрировать возможности тулкита), а с другой – максимально простым (чтобы показать, как просто с этим тулкитом работать). Рассматривались варианты блокнота, телефонной книжки итд, но недавно я увидел проект cmdradio и понял, что это именно то, что нужно – достаточно завернуть консольный плеер радио в приятный простой UI, и даже писать ничего не придётся. Благо код оригинальной программы был настолько прост, что состоял из одного файла в 400 строк. И вот за пару дней была написана обёртка над ней – cmdradio-visual. Выглядит это следующим образом:
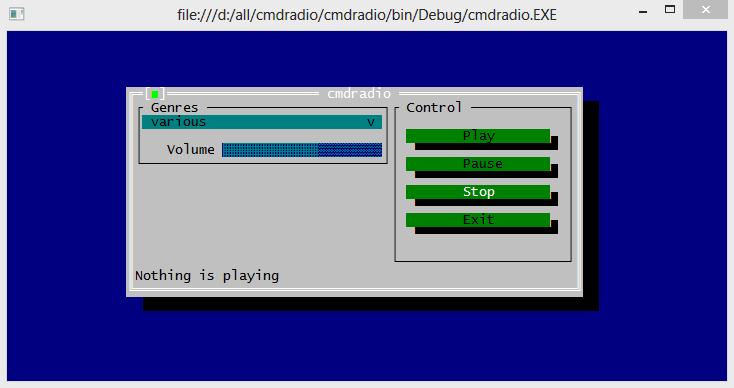
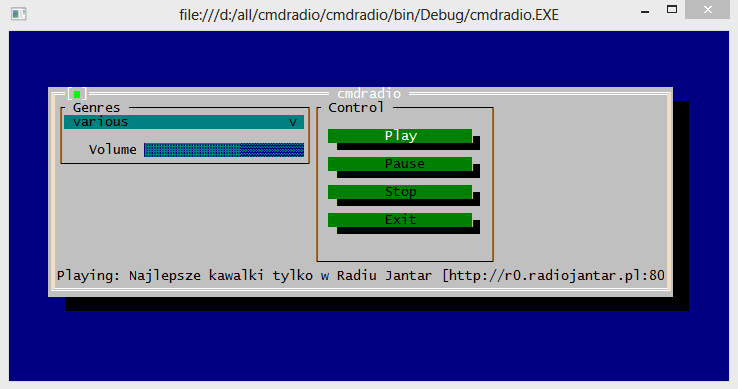
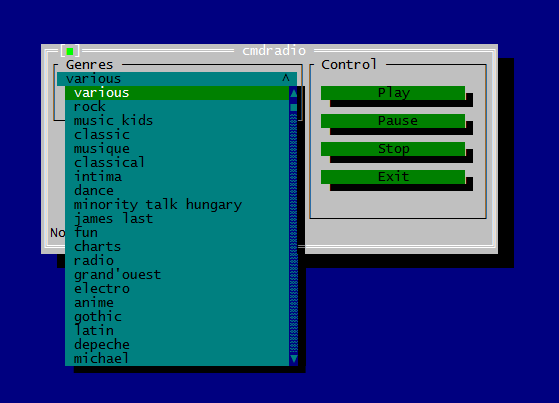
А кода буквально пара строк:
<Window Title="cmdradio" xmlns:x="http://consoleframework.org/xaml.xsd" xmlns:cmdradio="clr-namespace:cmdradio;assembly=cmdradio" MaxWidth="80"> <Panel> <Panel Orientation="Horizontal"> <GroupBox Title="Genres"> <Panel Orientation="Vertical"> <ComboBox ShownItemsCount="20" MaxWidth="30" SelectedItemIndex="{Binding Path=SelectedGenreIndex, Mode=OneWayToSource}" Items="{Binding Path=Genres, Mode=OneWay}"/> <Panel Orientation="Horizontal" HorizontalAlignment="Right" Margin="0,1,0,0"> <TextBlock Text="Volume"/> <cmdradio:VolumeControl Percent="{Binding Path=Volume}" Margin="1,0,0,0" Width="20" Height="1"/> </Panel> </Panel> </GroupBox> <GroupBox Title="Control"> <Panel Margin="1"> <Button Name="buttonPlay" Caption="Play" HorizontalAlignment="Stretch"/> <Button Name="buttonPause" Caption="Pause" HorizontalAlignment="Stretch"/> <Button Name="buttonStop" Caption="Stop" HorizontalAlignment="Stretch"/> <Button Name="buttonExit" Caption="Exit" HorizontalAlignment="Stretch"/> </Panel> </GroupBox> </Panel> <TextBlock HorizontalAlignment="Stretch" Text="{Binding Path=Status, Mode=OneWay}"/> </Panel> </Window> |
WindowsHost windowsHost = ( WindowsHost ) ConsoleApplication.LoadFromXaml( "cmdradio.WindowsHost.xml", null ); PlayerWindowModel playerWindowModel = new PlayerWindowModel( ); Window playerWindow = (Window)ConsoleApplication.LoadFromXaml("cmdradio.PlayerWindow.xml", playerWindowModel); Player player = new Player( ); playerWindow.FindChildByName< Button >( "buttonPlay" ).OnClick += ( sender, eventArgs ) => { player.cmd = new string[] { "play", ( string ) playerWindowModel.Genres[playerWindowModel.SelectedGenreIndex] }; player.Play(); }; playerWindow.FindChildByName< Button >( "buttonPause" ).OnClick += ( sender, eventArgs ) => { player.ReadCmd( new string[] {"pause"} ); }; playerWindow.FindChildByName< Button >( "buttonStop" ).OnClick += ( sender, eventArgs ) => { player.ReadCmd( new string[] {"stop"} ); }; playerWindow.FindChildByName< Button >( "buttonExit" ).OnClick += ( sender, eventArgs ) => { ConsoleApplication.Instance.Exit( ); }; windowsHost.Show( playerWindow ); foreach ( string s in player.GetGenres( )) { playerWindowModel.Genres.Add( s ); } playerWindowModel.PropertyChanged += ( sender, eventArgs ) => { if ( eventArgs.PropertyName == "Volume" ) { player.ReadCmd( new string[] { "volume", string.Format( "{0}", playerWindowModel.Volume ) }); } }; playerWindowModel.Status = player.Status; player.PropertyChanged += ( sender, eventArgs ) => { if ( eventArgs.PropertyName == "Status" ) { playerWindowModel.Status = player.Status; } }; ConsoleApplication.Instance.Run(windowsHost); |
По-моему, ещё никогда писать TUI-приложения не было так просто. Архив с программой можно скачать здесь.
JavaCC позволяет нам работать с набором токенов. Но часто бывает нужно сделать так, чтобы в некотором месте лексер не использовал набор основных токенов, а работал бы иначе. А потом снова возвращался к прежнему состоянию. Например, это может понадобиться для обработки многострочных комментариев – после встречи токена начала такого комментария лексер должен переключиться на режим, в котором бы игнорировалось всё, кроме токена его окончания. В случае комментариев это можно сделать стандартным для JavaCC способом – в настройке токенайзера:
SKIP : { // Однострочный комментарий < "//" (~["\r", "\n"])* > // Начало многострочного комментария - переход к другому состоянию лексера | < "/*" > : ML_COMMENT_STATE } // В этом состоянии есть существуют только два токена: конец комментария // и всё остальное. По нахождении токена конца комментария состояние возвращается в DEFAULT <ML_COMMENT_STATE> SKIP : { < "*/" > : DEFAULT | < ~[] > } |
А иногда бывает так, что перейти к другому набору токенов нужно не в токенайзере, а именно в парсере. Например, когда парсер встретил специальный токен и потом идут данные в другом формате. При парсинге различных DSL это может встречаться, например, в следующем варианте. Допустим у нас есть токен t_identifier, который начинается с буквы и далее идут буквы или цифры с подчёркиваниями. То есть – обычный идентификатор. Но мы хотим добавить поддержку директивы, синтаксис которой содержит ключевое слово, которое является валидным идентификатором. Например, “ignore”. Если не добавить специальный токен для этой сигнатуры, лексер при встрече с ним выплюнет нам токен-идентификатор. А если добавить токен
SKIP : { " " | "\t" | "\n" | "\r" } TOKEN: { <t_cat: "category"> | < tt_identifier: <LETTER> ( <LETTER>|<DIGIT> )* > // Строка в кавычках | < tt_string: "\"" (~["\"","\\","\n","\r"] | "\\" (["n","t","b","r","f","\\","\'","\""] | ["0"-"7"] (["0"-"7"])? | ["0"-"3"] ["0"-"7"] ["0"-"7"]))* "\"" > | < #LETTER: [ "_", "a"-"z", "A"-"Z", "а"-"я", "А"-"Я" ] > | < #DIGIT: [ "0"-"9"] > } // Да, для каждого лексического состояния нужно определить не только TOKEN, но и SKIP // и всё остальное, что используется <MYSTATE> SKIP : { " " | "\t" | "\n" | "\r" } <MYSTATE> TOKEN: { < tt_mystate_string: "\"" (~["\"","\\","\n","\r"] | "\\" (["n","t","b","r","f","\\","\'","\""] | ["0"-"7"] (["0"-"7"])? | ["0"-"3"] ["0"-"7"] ["0"-"7"]))* "\"" > | <tt_mystate_ignore: "ignore" > | <tt_mystate_semicolon: ";"> } // Часть того самого хака, необходимая для работы функции SetState(). TOKEN_MGR_DECLS : { void backup(int n) { input_stream.backup(n); } } // Функция SetState() необходима для безопасного перехода к другому лексическому состоянию // (так как токенайзер конвейеризирует поток токенов, и нужно этот конвейер сбросить). JAVACODE private void SetState(int state) { if (state != token_source.curLexState) { Token root = new Token(), last=root; root.next = null; // First, we build a list of tokens to push back, in backwards order while (token.next != null) { Token t = token; // Find the token whose token.next is the last in the chain while (t.next != null && t.next.next != null) t = t.next; // put it at the end of the new chain last.next = t.next; last = t.next; // If there are special tokens, these go before the regular tokens, // so we want to push them back onto the input stream in the order // we find them along the specialToken chain. if (t.next.specialToken != null) { Token tt=t.next.specialToken; while (tt != null) { last.next = tt; last = tt; tt.next = null; tt = tt.specialToken; } } t.next = null; }; while (root.next != null) { token_source.backup(root.next.image.length()); root.next = root.next.next; } jj_ntk = -1; token_source.SwitchTo(state); } } // Далее уже идёт наш код парсера private void Category() : { Token tname; } { <t_cat> <tt_string> ( "my state" MyState() | ";" ) } private void MyState() : { int entryState = token_source.curLexState; } { { SetState(MYSTATE); } <tt_mystate_string> [<tt_mystate_ignore> <tt_mystate_string>] <tt_mystate_semicolon> { SetState(entryState); } } |
Неудобство заключается в том, что в изменённом (не-DEFAULT) состоянии нельзя использовать строковые литералы просто так, не добавляя для них токены (то есть вместо “;” мы должны записать <tt_mystate_semicolon>). Возможно, это баг, но может оказаться и специальным ограничением. Ветку с обсуждением этой проблемы можно прочитать здесь. Впрочем, несмотря на эту проблему, у нас всё получилось, и мы вернули себе полный контроль над процессом.
4